Can AI Research Itself? An Autonomous AI Researcher Running Overnight
Autonomous AI agents, LLM training optimization, and machine learning experiments on Apple Silicon

"Research is now entirely the domain of autonomous AI agent swarms." — Andrej Karpathy, from the fictional preface of the autoresearch README
Let's do a thought experiment: What if you told an AI agent "improve this model" and went to sleep? When you woke up, 100 experiments had been run, the best results saved, and the failed ones reverted?
This is no longer a thought experiment. And behind this idea is one of the most influential figures in the AI world.
Karpathy's Revolutionary Step
The autoresearch project was created by Andrej Karpathy. For those unfamiliar: he was Tesla's AI Director for autonomous driving, a founding member of OpenAI, and taught deep learning at Stanford. He holds a unique position in AI as an "educator-engineer" — someone who both builds complex systems and explains them so anyone can understand.
With autoresearch, Karpathy automated AI research itself. This is a pivotal moment in AI history. Why?
Until now, AI research worked like this: a human researcher forms a hypothesis, writes code, runs an experiment, analyzes results, and loops back. This cycle takes weeks, months. Karpathy's approach compresses this loop to 5 minutes and removes the human from it.
The project's README contains a fictional preface set in 2026. Karpathy envisions a future where research has been entirely delegated to autonomous AI agents. Instead of editing Python files directly, humans write instructions in a Markdown file called program.md. In other words, humans don't write code — they write research strategy.
The reason this is revolutionary is simple: if an AI agent can run an experiment every 5 minutes, it can run 100 experiments overnight. It can complete in one night what would take a human researcher weeks. And this isn't just for LLM training — the same pattern applies to any "experimental optimization" problem.
What Is "Autoresearch"?
Karpathy's original autoresearch was designed for NVIDIA GPUs. Since I wanted to try it on my Apple Silicon Mac, I used the community-developed autoresearch-macos fork. This fork removes the FlashAttention dependency and adds PyTorch's native attention mechanism and Metal Performance Shaders (MPS) support.
The concept is simple but powerful:
- There's a small GPT model (training code in a single file)
- Give this code to an AI agent
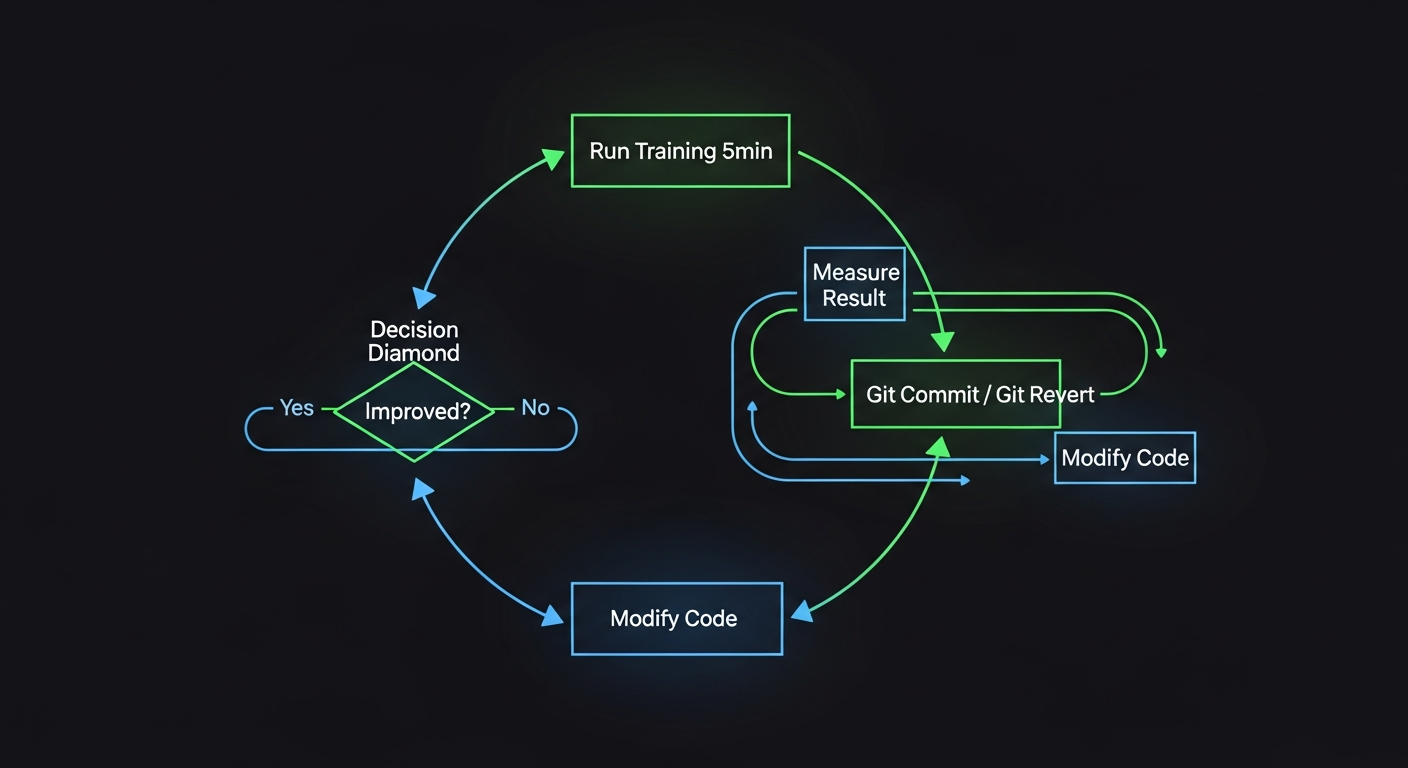
- The agent modifies the code → runs a 5-minute training experiment → evaluates the result
- If the result improves, keep the change; if not, revert it
- Repeat indefinitely
The agent acts like a researcher: form a hypothesis, run the experiment, measure the result, make a decision.
Why Did I Do This?
I was genuinely curious: does an autonomous AI research loop actually work?
The "AI agent" concept has been getting a lot of attention lately. But most examples are either demo-level or in highly controlled environments. I wanted to see:
- Can an agent truly make meaningful decisions on its own?
- Does this work on an Apple Silicon Mac (i.e., an ordinary developer's computer)?
- Are the results reliable?
The answers to these questions would determine how I use autonomous agents in my own projects going forward.
Technical Setup
The system is surprisingly minimal:
autoresearch-macos/
├── prepare.py # Data preparation, tokenizer (untouched)
├── train.py # Model + training code (agent modifies this)
├── program.md # Instructions for the agent
└── results.tsv # Experiment results
Model: An 11.5 million parameter GPT model. Tiny compared to large language models — roughly 1/100,000th of GPT-4. But ideal for experimentation.
Metric: val_bpb (validation bits per byte). Lower = better. It measures how well the model predicts the next character in the text it sees.
Duration: Each experiment runs for exactly 5 minutes. This fixed duration makes apples-to-apples comparisons possible.
Optimizer: Muon — a next-generation optimizer. Unlike classic AdamW, it updates by projecting weight matrices into orthogonal space. Roughly speaking: "it smooths gradients and takes cleaner steps." For the technically curious: it uses polar decomposition via Newton-Schulz iteration on matrix parameters — normalizing the magnitude of each update while preserving its direction.
What Did I Try, What Happened?
I ran 10 experiments. Here's the story:
What Worked: Reducing Batch Size
Original setting: 65,536 tokens processed per optimizer step. I halved it to 32,768.
Why did it work? Smaller batch = each step completes faster = more steps in 5 minutes. MPS (Metal Performance Shaders — Apple Silicon's GPU compute infrastructure) already delivers low throughput, so "speed" mattered more than anything.
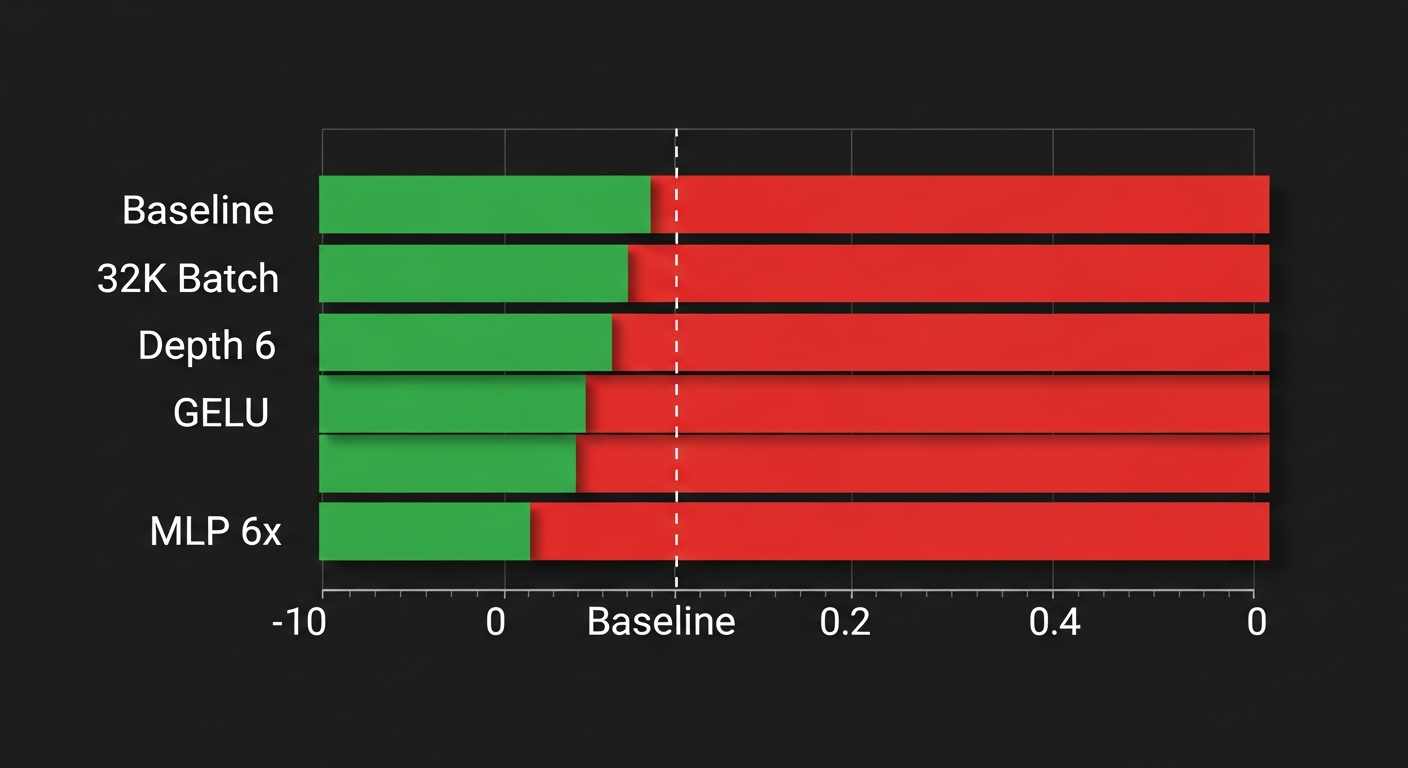
Baseline: 126 steps → val_bpb = 1.584
32K batch: 243 steps → val_bpb = 1.477 (6.8% improvement)
There's a trade-off here: larger batches generally yield more stable gradients, but our bottleneck was compute speed, not statistical stability.
What Failed
| Experiment | Idea | Result | Why | |------------|------|--------|-----| | Depth 4→6 | Deeper model | 2.139 (worse) | Larger model = slower per step = fewer steps | | Batch 16K | Even smaller batch | 1.952 (worse) | Too-small batch increased gradient noise | | GELU activation | Different activation | 1.895 (worse) | ReLU² more efficient at this model size | | MLP 6x width | Wider MLP | 1.488 (~same) | Extra parameters, no gain | | Remove value embed | Simplification | 1.644 (worse) | This component actually helps |
The MPS Stall Problem
The most interesting finding was a technical limitation: Apple Silicon's MPS backend randomly freezes.
In some training runs, a single step took 400-900 seconds (normally ~1.3 seconds). This "stall" phenomenon invalidated 5 out of 10 experiments. Running the same configuration twice gave different results:
Same code, run 1: val_bpb = 1.477 (243 steps)
Same code, run 2: val_bpb = 1.535 (192 steps)
This stems from an issue in MPS's Metal compute shader scheduling mechanism. PyTorch's MPS backend isn't as mature as CUDA — especially during large matrix multiplications, GPU-CPU synchronization sometimes stalls.
Does the Autonomous Agent Actually Work?
Short answer: Yes, but conditionally.
What works well:
- The agent manages the experiment loop flawlessly: modify code → git commit → run → read results → decide → revert if needed
- It self-corrects when it makes mistakes (e.g., when it hit an assertion error, it adjusted the related parameter)
- It consistently records results
Limitations:
- The agent's "creativity" is limited — it mostly tried hyperparameter changes, not radical architectural modifications
- MPS stalls made it difficult to assess result reliability
- A human researcher would probably find the batch size optimization in the first 2-3 experiments and then make more strategic attempts
This reflects a general characteristic of current AI agents: excellent at tactics, room for growth in strategy.
What Did I Learn?
1. The "Fixed-Budget Experiment" Pattern Is Powerful
Having each experiment run for exactly 5 minutes makes comparison straightforward. This pattern can be applied beyond machine learning:
- Prompt optimization: Evaluate 100 different prompts against the same test set
- Code performance: Benchmark different algorithms with a fixed time budget
- A/B testing: Compare variants with a fixed traffic budget
2. Apple Silicon Is "Sufficient But Unreliable" for ML
M-series chips are great for prototyping and inference. But for serious training research:
- MPS stalls make results inconsistent
- The CUDA ecosystem (FlashAttention, torch.compile, etc.) is far more mature
- Cloud GPU (RunPod, Lambda Labs, GCP) costs $1-3/hour — running 100 experiments overnight costs ~$5
3. Simplicity Wins
The biggest improvement (6.8%) came from the simplest change: halving the batch size. Architectural changes (GELU, MLP widening, removing value embeddings) either didn't work or made no difference.
This is a common finding in machine learning: hyperparameter optimization is often more effective than architectural changes. Tuning the learning rate correctly does more than a fancy attention mechanism.

What Should Come Next?
I consider this experiment a proof of concept. To unlock the real potential:
Short Term
- Repeat on cloud GPU: Run the same experiments on an NVIDIA A100 or H100. Without MPS stalls, results would be far more reliable. Plus optimizations like
torch.compileand FlashAttention come into play. - Run longer: I ran 10 experiments on this Mac, taking ~1 hour. Running 100+ experiments overnight on a cloud GPU would reveal real trends.
Medium Term
- Apply to different domains: This "autonomous experiment loop" isn't just for LLM training. Similar loops can be built for prompt engineering, RAG pipeline optimization, even web performance testing.
- Multi-agent coordination: One agent tries architectural changes while another does hyperparameter search. Parallel research.
Long Term
- Build a "research assistant" platform: Fixed-budget experiments + automated evaluation + git-based version tracking = overnight research infrastructure. This could be developed as an internal tool.
The Big Picture: Revolutionary Steps in AI Research
Karpathy's autoresearch isn't an isolated project — it's one in a series of revolutionary steps in artificial intelligence. Putting these on a timeline helps us understand where we're heading:
- 2017 — Transformer architecture: Google's "Attention Is All You Need" paper started it all
- 2020 — Scaling laws: OpenAI showed that scaling models predictably improves performance
- 2022 — ChatGPT: AI left research labs and reached everyone
- 2024 — AI agents: AI began being used not just to answer questions, but to "do work"
- 2025-26 — Autonomous AI research: With Karpathy's autoresearch, AI began researching itself
Why is this last step so significant? Because there's a recursion here: AI is being used to improve AI. This could theoretically create exponential acceleration — each improvement making the next one faster and better.
Karpathy already foresaw this. The fictional preface in his project's README envisions a future where humans no longer write Python, but instead give AI agents research strategy through program.md files. Humans answer "what should be researched," AI handles "how to research it."
This isn't just an efficiency gain. It's a fundamental change in how research is done. And the fact that someone like Karpathy shares this as open source makes this revolution accessible to everyone.
Closing
Telling an AI agent to "do research" is no longer science fiction. Karpathy's autoresearch project made this idea concrete and functional. The experiment I described in this post — 10 autonomous experiments on an Apple Silicon Mac — is a small sample, but the idea behind it is massive: AI is no longer just our tool, it's our research partner.
Of course, it's not perfect in its current form. The agent's creativity is limited, MPS is unreliable, results are noisy. But this is just like deep learning in the early 2010s — "it works, but it's fragile." And from that fragile beginning, we arrived at today's frontier models.
Karpathy showed the way once again. It's up to us to walk that path, adding our own creativity along the way.

All experiments in this post were conducted on an Apple Silicon Mac using autoresearch-macos, a macOS fork of Andrej Karpathy's autoresearch project. Full experiment results are available in the autoresearch/mar9 branch.
Autonomous AI agents, LLM training optimization, and machine learning experiments on Apple Silicon