Yapay Zeka Kendi Kendini Araştırabilir mi? Bir Gece Boyunca Çalışan AI Araştırmacısı
Otonom AI agent'lar, LLM eğitim optimizasyonu ve Apple Silicon'da makine öğrenmesi deneyleri

"Araştırma artık tamamen otonom AI agent sürülerinin alanı." — Andrej Karpathy, autoresearch README'sindeki kurgusal önsözden
Bir düşünce deneyi yapalım: Ya bir yapay zeka agent'ına "şu modeli iyileştir" deyip uyusaydın? Sabah kalktığında 100 deney yapılmış, en iyi sonuçlar kaydedilmiş, başarısız olanlar geri alınmış olsaydı?
Bu artık bir düşünce deneyi değil. Ve bu fikrin arkasında yapay zeka dünyasının en etkili isimlerinden biri var.
Karpathy'nin Devrimsel Adımı
autoresearch projesini Andrej Karpathy yarattı. Karpathy'yi tanımayanlar için kısa bir özet: Tesla'nın otonom sürüş yapay zeka direktörüydü, OpenAI'ın kurucu ekibinde yer aldı, Stanford'da derin öğrenme dersleri verdi. Yapay zeka alanında "eğitimci-mühendis" olarak benzersiz bir konuma sahip — karmaşık kavramları hem inşa ediyor hem de herkesin anlayabileceği şekilde açıklıyor.
Karpathy, autoresearch ile yapay zeka araştırmasının kendisini otomatikleştirdi. Bu, AI tarihinde önemli bir kırılma noktası. Neden mi?
Bugüne kadar AI araştırması şöyle çalışıyordu: bir insan araştırmacı hipotez kurar, kod yazar, deney çalıştırır, sonuçları analiz eder, tekrar başa döner. Bu döngü haftalar, aylar sürer. Karpathy'nin yaklaşımı bu döngüyü 5 dakikaya sıkıştırıyor ve insanı döngüden çıkarıyor.
Projenin README'sinde, 2026'dan yazılmış kurgusal bir önsöz var. Karpathy burada araştırmanın tamamen otonom AI agent'lara devredildiği bir gelecek çiziyor. İnsanlar artık doğrudan Python dosyalarını düzenlemek yerine, program.md adlı bir Markdown dosyasıyla agent'lara talimat veriyor. Yani insanlar kod yazmıyor, araştırma stratejisi yazıyor.
Bu fikrin devrimsel olmasının sebebi basit: eğer bir AI agent 5 dakikada bir deney yapabiliyorsa, gece boyunca 100 deney yapabilir. Bir insan araştırmacının haftalarca sürecek çalışmasını bir gecede tamamlayabilir. Ve bu sadece LLM eğitimi için değil — aynı kalıp herhangi bir "deneysel optimizasyon" problemine uygulanabilir.
Nedir Bu "Autoresearch"?
Karpathy'nin orijinal autoresearch projesi NVIDIA GPU'lar için tasarlandı. Ben ise Apple Silicon Mac'imde denemek istediğim için, topluluk tarafından geliştirilen autoresearch-macos fork'unu kullandım. Bu fork, FlashAttention bağımlılığını kaldırıp PyTorch'un native attention mekanizmasını ve Metal Performance Shaders (MPS) desteğini ekliyor.
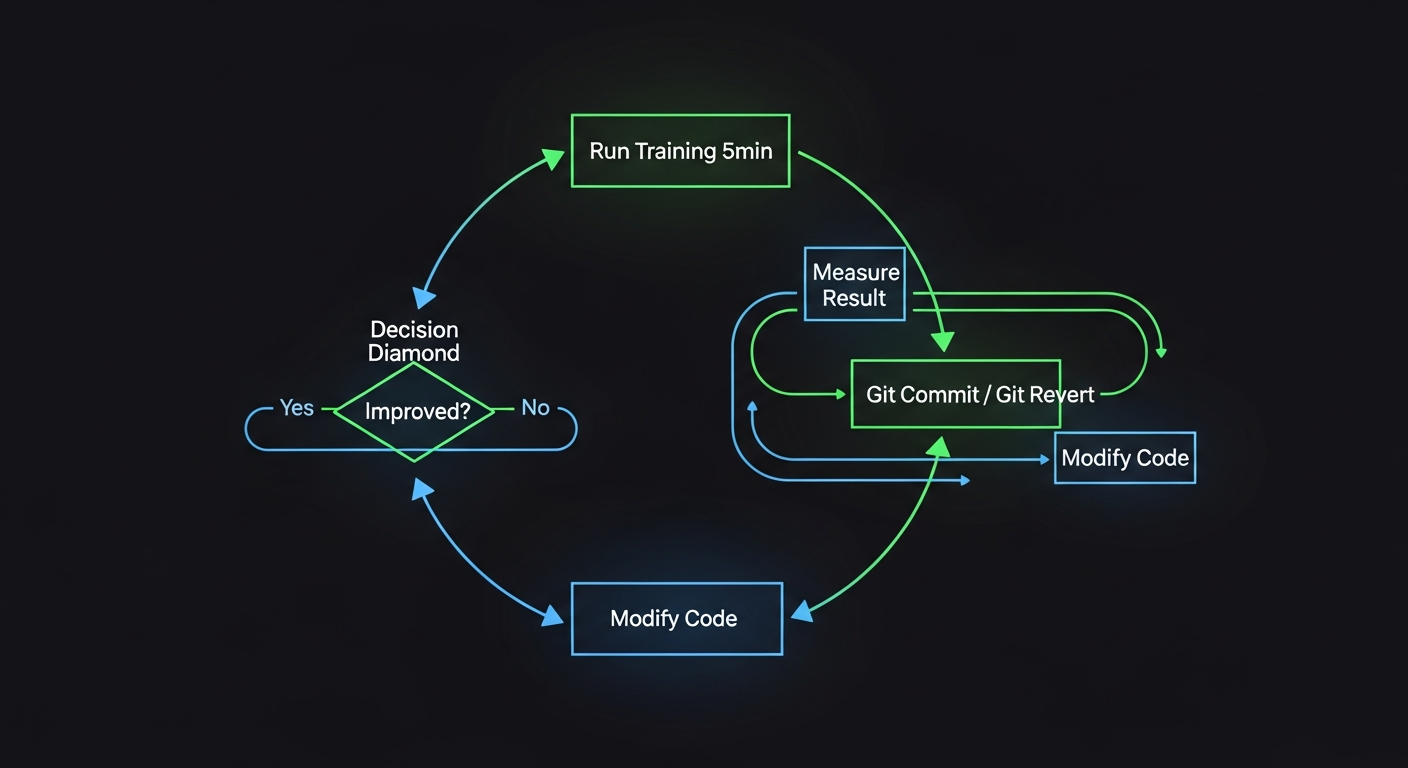
Konsepti basit ama güçlü:
- Küçük bir GPT modeli var (eğitim kodu tek bir dosyada)
- Bir AI agent'a bu kodu ver
- Agent kodu değiştirir → 5 dakikalık bir eğitim deneyi çalıştırır → sonucu değerlendirir
- Sonuç iyiyse değişikliği tutar, kötüyse geri alır
- Sonsuza kadar tekrar et
Yani agent bir araştırmacı gibi davranıyor: hipotez kur, deney yap, sonucu ölç, karar ver.
Neden Yaptım?
Aslında merak ettim: otonom AI araştırma döngüsü gerçekten çalışıyor mu?
Son dönemde "AI agent" kavramı çok konuşuluyor. Ama çoğu örnek ya demo düzeyinde ya da çok kontrollü ortamlarda. Ben şunu görmek istedim:
- Bir agent gerçekten kendi başına anlamlı kararlar verebilir mi?
- Apple Silicon Mac'te (yani sıradan bir geliştirici bilgisayarında) bu iş döner mi?
- Sonuçlar güvenilir mi?
Bu soruların cevabı, ileride kendi projelerimde otonom agent'ları nasıl kullanacağımı belirleyecekti.
Teknik Kurulum
Sistem şaşırtıcı derecede minimal:
autoresearch-macos/
├── prepare.py # Veri hazırlığı, tokenizer (dokunulmaz)
├── train.py # Model + eğitim kodu (agent bunu değiştirir)
├── program.md # Agent'a talimatlar
└── results.tsv # Deney sonuçları
Model: 11.5 milyon parametreli bir GPT modeli. Büyük dil modellerine kıyasla çok küçük — GPT-4'ün yaklaşık 100.000'de biri. Ama deney yapmak için ideal.
Metrik: val_bpb (validation bits per byte). Düşük = daha iyi. Model, gördüğü metindeki bir sonraki karakteri ne kadar iyi tahmin edebildiğini ölçüyor.
Süre: Her deney tam 5 dakika sürüyor. Bu sabit süre sayesinde elmalarla elmaları karşılaştırabiliyorsun.
Optimizer: Muon — yeni nesil bir optimizer. Klasik AdamW'den farklı olarak, ağırlık matrislerini ortogonal uzaya yansıtarak güncelleme yapıyor. Kabaca söylemek gerekirse: "gradyanları düzleştirip daha temiz adımlar atıyor." Teknik detayı merak ediyorsan, matris parametreleri için polar decomposition kullanarak Newton-Schulz iterasyonu yapıyor — bu da her güncellemenin "yönünü" korurken büyüklüğünü normalize ediyor.
Ne Denedim, Ne Oldu?
10 deney yaptım. İşte hikaye:
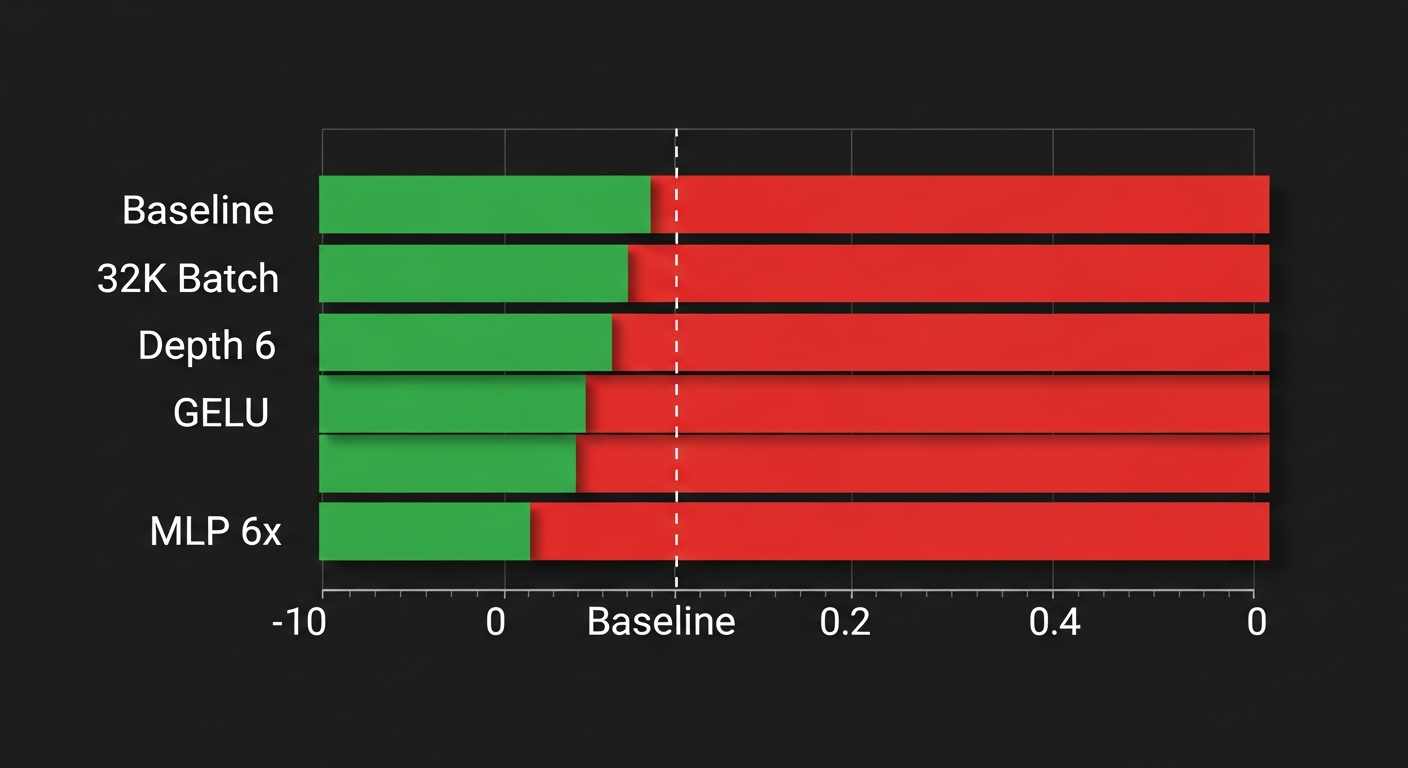
Başarılı Olan: Batch Size Küçültmek
Orijinal ayar: her optimizer adımında 65.536 token işleniyor. Bunu 32.768'e düşürdüm.
Neden işe yaradı? Daha küçük batch = her adım daha hızlı tamamlanıyor = 5 dakikada daha fazla adım atılıyor. MPS (Metal Performance Shaders — Apple Silicon'un GPU hesaplama altyapısı) zaten düşük throughput veriyor, bu yüzden "hız" her şeyden önemliydi.
Baseline: 126 adım → val_bpb = 1.584
32K batch: 243 adım → val_bpb = 1.477 (%6.8 iyileşme)
Burada bir trade-off var: büyük batch genelde daha kararlı gradyanlar verir ama bizim darboğazımız hesaplama hızıydı, istatistiksel kararlılık değil.
Başarısız Olanlar
| Deney | Fikir | Sonuç | Neden | |-------|-------|-------|-------| | Depth 4→6 | Daha derin model | 2.139 (kötü) | Daha büyük model = her adım daha yavaş = daha az adım | | Batch 16K | Daha da küçük batch | 1.952 (kötü) | Çok küçük batch gradient noise'u artırdı | | GELU aktivasyon | Farklı aktivasyon | 1.895 (kötü) | ReLU² bu model boyutunda daha verimli | | MLP 6x genişlik | Daha geniş MLP | 1.488 (~eşit) | Ekstra parametre, kazanım yok | | Value embed kaldır | Basitleştirme | 1.644 (kötü) | Bu bileşen aslında işe yarıyormuş |
MPS Stall Sorunu
En ilginç bulgu teknik bir kısıttı: Apple Silicon'un MPS backend'i rastgele donuyor.
Bazı eğitim çalıştırmalarında tek bir adım 400-900 saniye sürüyordu (normalde ~1.3 saniye). Bu "stall" fenomeni, 10 deneyden 5'ini geçersiz kıldı. Aynı konfigürasyonu iki kez çalıştırdığımda farklı sonuçlar aldım:
Aynı kod, 1. çalıştırma: val_bpb = 1.477 (243 adım)
Aynı kod, 2. çalıştırma: val_bpb = 1.535 (192 adım)
Bu, MPS'in Metal compute shader zamanlama mekanizmasındaki bir sorundan kaynaklanıyor. PyTorch'un MPS backend'i CUDA kadar olgunlaşmamış — özellikle büyük matris çarpımlarında bazen GPU-CPU senkronizasyonu tıkanıyor.
Otonom Agent Gerçekten Çalışıyor mu?
Kısa cevap: Evet, ama koşullu.
İşe yarayan kısım:
- Agent deney döngüsünü kusursuz yönetiyor: kod değiştir → git commit → çalıştır → sonuç oku → karar ver → gerekirse revert
- Hata yaptığında kendini düzeltiyor (örneğin bir assertion hatası aldığında ilgili parametreyi de değiştirdi)
- Sonuçları tutarlı şekilde kaydediyor
Sınırlamalar:
- Agent'ın "yaratıcılığı" sınırlı — çoğunlukla hiperparametre değişiklikleri denedi, radikal mimari değişiklikler yapmadı
- MPS stall'ları nedeniyle sonuçların güvenilirliğini değerlendirmek zorlaştı
- Bir insan araştırmacı muhtemelen ilk 2-3 deneyde batch size optimizasyonunu bulur ve sonra daha stratejik denemeler yapardı
Bu, şu ana kadarki AI agent'ların genel bir özelliğini yansıtıyor: taktik düzeyde çok iyi, strateji düzeyinde gelişmeye açık.
Ne Öğrendim?
1. "Sabit Bütçeli Deney" Kalıbı Güçlü
Her deneyin tam 5 dakika sürmesi, karşılaştırmayı çok kolaylaştırıyor. Bu kalıp makine öğrenmesinin ötesinde de kullanılabilir:
- Prompt optimizasyonu: 100 farklı prompt'u aynı test seti üzerinde değerlendir
- Kod performansı: Farklı algoritmaları sabit sürede benchmark'la
- A/B testleri: Sabit trafik bütçesiyle varyantları karşılaştır
2. Apple Silicon ML İçin "Yeterli Ama Güvenilmez"
M serisi çipler prototipleme ve inference için harika. Ama ciddi eğitim araştırması için:
- MPS stall'ları sonuçları tutarsız yapıyor
- CUDA ekosistemi (FlashAttention, torch.compile, vb.) çok daha olgun
- Cloud GPU (RunPod, Lambda Labs, GCP) saatlik maliyeti $1-3 arasında — bir gecede 100 deney yapmak ~$5'a mal olur
3. Basitlik Kazanır
En büyük iyileşme (%6.8) en basit değişiklikten geldi: batch size'ı yarıya düşürmek. Mimari değişiklikler (GELU, MLP genişletme, value embedding kaldırma) ya işe yaramadı ya da fark yaratmadı.
Bu, makine öğrenmesinde sık karşılaşılan bir durum: hiperparametre optimizasyonu çoğu zaman mimari değişikliklerden daha etkili. Fancy bir attention mekanizması yerine learning rate'i doğru ayarlamak daha çok iş yapar.

Sonraki Adım Ne Olmalı?
Bu deneyi bir "proof of concept" olarak değerlendiriyorum. Gerçek potansiyeli açığa çıkarmak için:
Kısa Vadede
- Cloud GPU'da tekrarlamak: Aynı deneyleri bir NVIDIA A100 veya H100 üzerinde çalıştırmak. MPS stall'ları olmadan, sonuçlar çok daha güvenilir olur. Ayrıca
torch.compileve FlashAttention gibi optimizasyonlar da devreye girer. - Daha uzun süre çalıştırmak: Bu Mac'te 10 deney yaptım, ~1 saat sürdü. Bir cloud GPU'da gece boyunca 100+ deney çalıştırmak, gerçek trendleri ortaya çıkarır.
Orta Vadede
- Farklı alanlara uygulamak: Bu "otonom deney döngüsü" sadece LLM eğitimi için değil. Prompt mühendisliği, RAG pipeline optimizasyonu, hatta web performans testleri için benzer döngüler kurulabilir.
- Çoklu agent koordinasyonu: Bir agent mimari değişiklikleri denerken, başka bir agent hiperparametre araması yapabilir. Paralel araştırma.
Uzun Vadede
- Kendi "araştırma asistanı" platformu: Sabit bütçeli deney + otomatik değerlendirme + git tabanlı versiyon takibi = gece boyunca çalışan araştırma altyapısı. Bu bir iç araç olarak geliştirilebilir.
Büyük Resim: AI Araştırmasında Devrimsel Adımlar
Karpathy'nin autoresearch'ü tek başına bir proje değil — yapay zeka alanında art arda gelen devrimsel adımlardan biri. Bu adımları bir zaman çizelgesine koymak, nereye doğru gittiğimizi anlamayı kolaylaştırır:
- 2017 — Transformer mimarisi: Google'ın "Attention Is All You Need" makalesi her şeyi başlattı
- 2020 — Scaling laws: OpenAI, modeli büyütmenin öngörülebilir şekilde performansı artırdığını gösterdi
- 2022 — ChatGPT: AI, araştırma laboratuvarlarından çıkıp herkesin eline geçti
- 2024 — AI agent'lar: AI'ın sadece cevap vermek değil, "iş yapmak" için kullanılmaya başlanması
- 2025-26 — Otonom AI araştırması: Karpathy'nin autoresearch'ü ile AI, kendi kendini araştırmaya başladı
Bu son adım neden bu kadar önemli? Çünkü burada bir özyineleme (recursion) var: AI, AI'ı geliştirmek için kullanılıyor. Bu, teorik olarak üstel bir ivmelenme yaratabilir — her iyileşme bir sonraki iyileşmeyi daha hızlı ve daha iyi yapabilir.
Karpathy bunu zaten öngörmüş. Projesinin README'sindeki kurgusal önsöz, insanların artık Python yazmadığı, bunun yerine program.md dosyalarıyla AI agent'lara araştırma stratejisi verdiği bir gelecek çiziyor. İnsanlar "ne araştırılsın" sorusunu yanıtlıyor, "nasıl araştırılsın" kısmını AI hallediyor.
Bu sadece bir verimlilik artışı değil. Bu, araştırma yapma biçiminin kendisinin değişmesi. Ve Karpathy gibi birinin bunu açık kaynak olarak paylaşması, bu devrimi herkes için erişilebilir kılıyor.
Kapanış
Bir yapay zeka agent'ına "araştırma yap" demek artık bilim kurgu değil. Karpathy'nin autoresearch projesi, bu fikri somut ve çalışır bir hale getirdi. Bu yazıda anlattığım deney — bir Apple Silicon Mac üzerinde 10 otonom deney — küçük bir örnek ama arkasındaki fikir devasa: AI artık sadece aracımız değil, araştırma ortağımız.
Tabii ki bugünkü haliyle mükemmel değil. Agent'ın yaratıcılığı sınırlı, MPS güvenilmez, sonuçlar gürültülü. Ama bu tıpkı 2010'ların başındaki derin öğrenme gibi — "çalışıyor ama kırılgan." Ve o kırılgan başlangıçtan bugünkü frontier modellere geldik.
Karpathy bir kez daha yol gösterdi. Bize düşen, bu yolda kendi yaratıcılığımızı da ekleyerek yürümek.

Bu yazıdaki tüm deneyler, Andrej Karpathy'nin autoresearch projesinin macOS fork'u olan autoresearch-macos kullanılarak bir Apple Silicon Mac üzerinde gerçekleştirildi. Deney sonuçlarının tamamı autoresearch/mar9 branch'inde mevcuttur.
Otonom AI agent'lar, LLM eğitim optimizasyonu ve Apple Silicon'da makine öğrenmesi deneyleri